


Projects:
Elucidating the Role of Feature Normalization in IJEPA [code] [paper]
In the standard image joint embedding predictive architecture (IJEPA), features at the output of the teacher encoder are layer normalized (LN) before serving as a distillation target for the student encoder and predictor. We propose that this feature normalization disrupts the natural energy hierarchy of visual tokens, where high-energy tokens (those with larger L2 norms) encode semantically important image regions. LN forces all features to have identical L2 norms, effectively equalizing their energies and preventing the model from prioritizing semantically rich regions. We find that IJEPA models trained with feature LN exhibit loss maps with significant checkerboard-like artifacts. We propose that feature LN be replaced with a DynTanh activation as the latter better preserves token energies and allows high-energy tokens to greater contribute to the prediction loss. We show that IJEPA trained with feature DynTanh exhibits a longer-tailed loss distribution and fixes the checkerboard artifacts in the loss map. Our empirical results show that our simple modification improves ImageNet linear probe accuracy from 38% to 42.7% for ViT-Small and reduces RMSE by 0.08 on NYU Depth V2 monocular depth estimation. These results suggest that preserving natural token energies is crucial for effective self-supervised visual representation learning.

In the standard image joint embedding predictive architecture (IJEPA), features at the output of the teacher encoder are layer normalized (LN) before serving as a distillation target for the student encoder and predictor. We propose that this feature normalization disrupts the natural energy hierarchy of visual tokens, where high-energy tokens (those with larger L2 norms) encode semantically important image regions. LN forces all features to have identical L2 norms, effectively equalizing their energies and preventing the model from prioritizing semantically rich regions. We find that IJEPA models trained with feature LN exhibit loss maps with significant checkerboard-like artifacts. We propose that feature LN be replaced with a DynTanh activation as the latter better preserves token energies and allows high-energy tokens to greater contribute to the prediction loss. We show that IJEPA trained with feature DynTanh exhibits a longer-tailed loss distribution and fixes the checkerboard artifacts in the loss map. Our empirical results show that our simple modification improves ImageNet linear probe accuracy from 38% to 42.7% for ViT-Small and reduces RMSE by 0.08 on NYU Depth V2 monocular depth estimation. These results suggest that preserving natural token energies is crucial for effective self-supervised visual representation learning.
A Theory for Coupling Generation and Compression: I formalize two-stage generation as a bilevel optimization problem and
offer a theory to improve the alignment between stage 1 models (VAEs VQGANS,
tokenizers) and stage 2 models (Diffusion, autoregressive, or other generative
models)
Image Self Supervised Learning on a Shoestring : IJEPA-Enhanced: I create a technique for quickly training self supervised image encoders on
a single GPU. I optimize for training throughput. The code allows you to train
a ViT-S at a rate of 1300 medium sized images per second. I release the
training code here:
IJEPA-enhanced 
 IJEPA-Enhanced uses masked latent prediction to train a machine learning model
how to 'see'. source code available
IJEPA-Enhanced uses masked latent prediction to train a machine learning model
how to 'see'. source code available
IJEPA-Enhanced uses masked latent prediction to train a machine learning model
how to 'see'.Generative modelling of compressed image file bits: Do you have issues with achieving GPU saturation because of your
dataloading load? Don't you wish you could train directly on compressed image
files? Say no more! I trained llama to directly generate the bits of a lossy
image compression file format called spiht. Check out my report! There will be
more coming soon.
source code available
spiht-py: An
implementation of the SPIHT algorithm in
Rust, with Python bindings SPIHT is an lossy image compression algorithm. Like
JPG, it can reduce the amount of bits required to store images. Unlike JPG,
the SPIHT bitstream can be interrupted at any point and the entire image
decoded. There are no 'blocks' in the SPIHT algorithm.
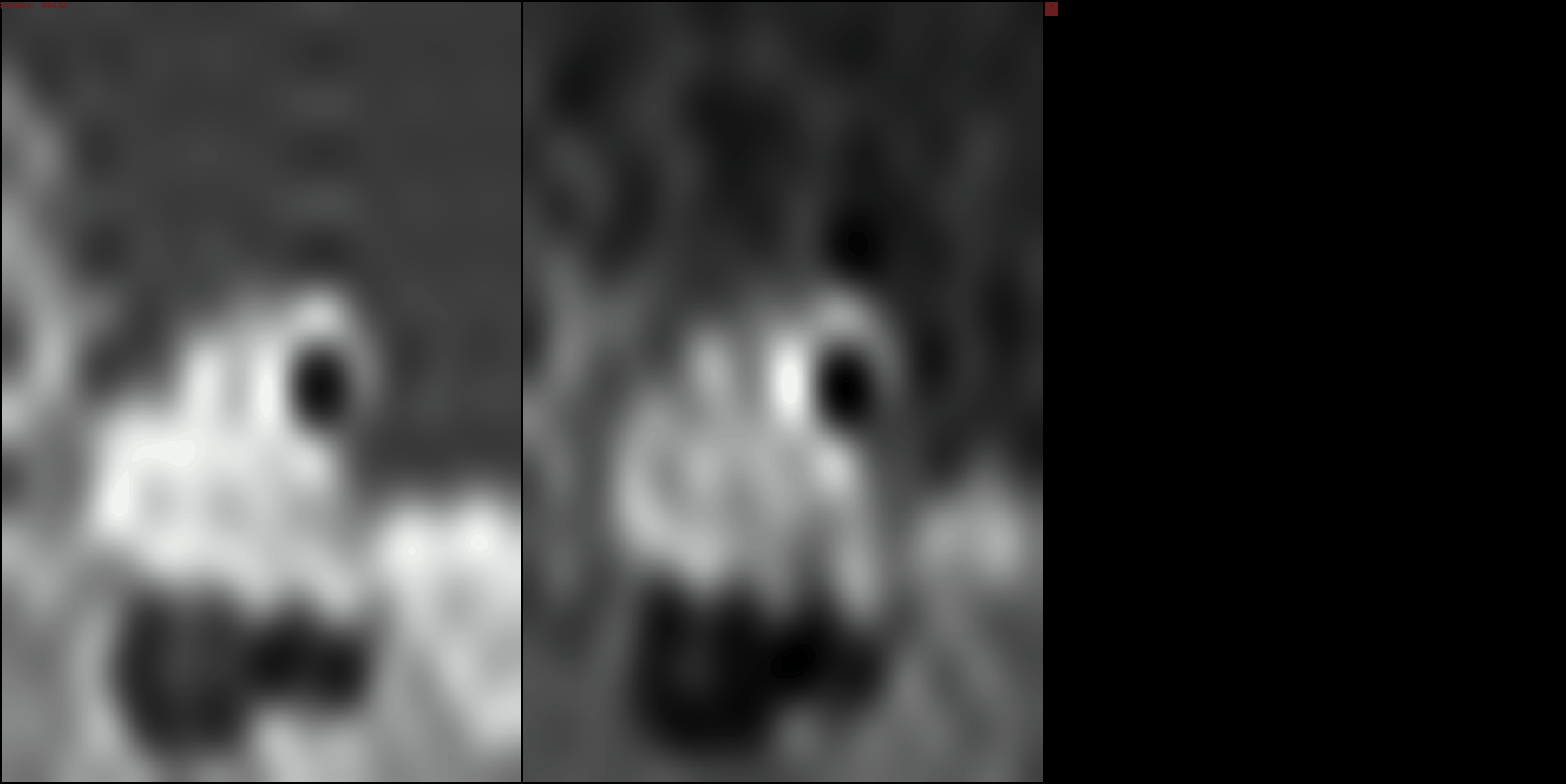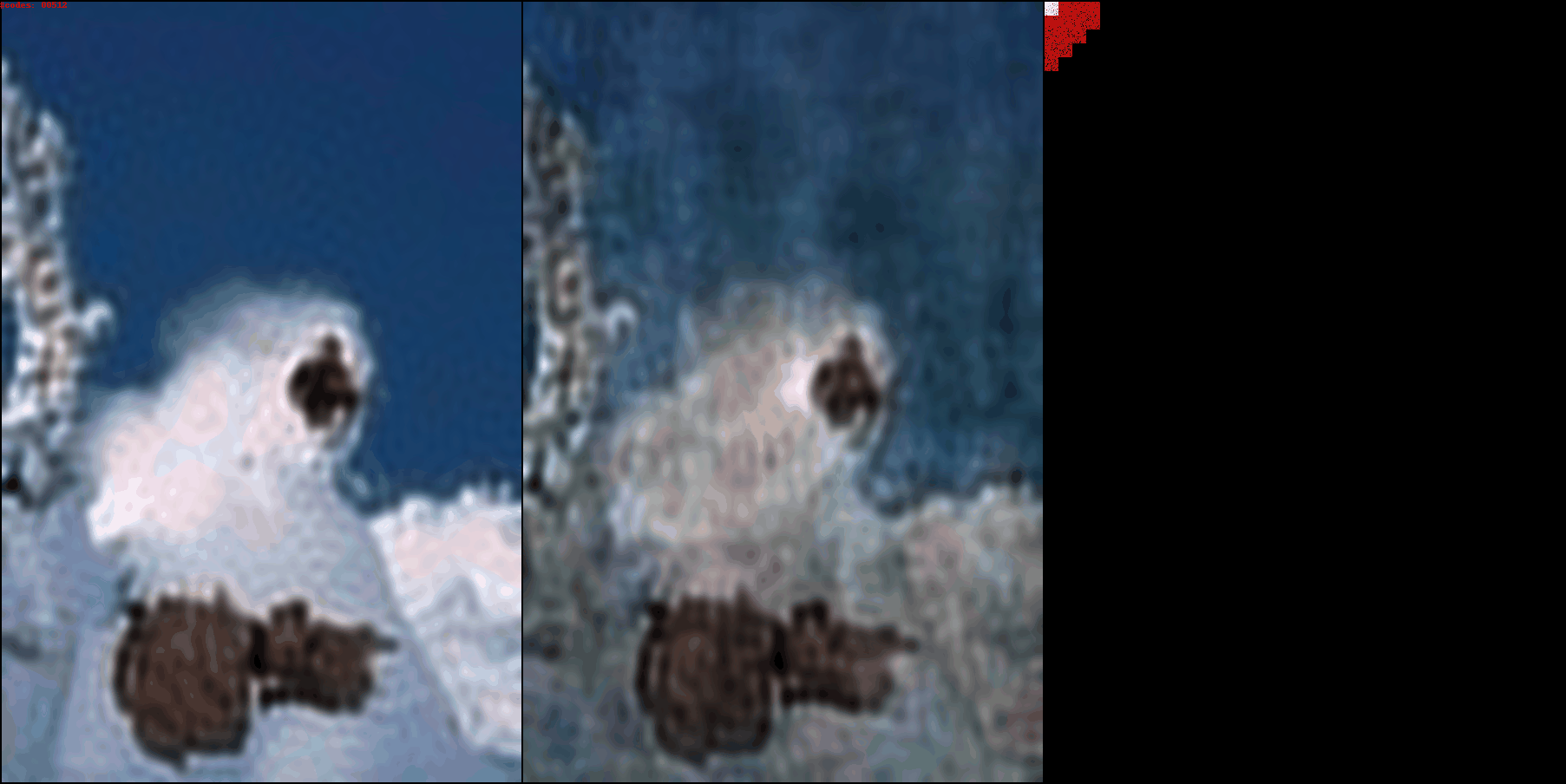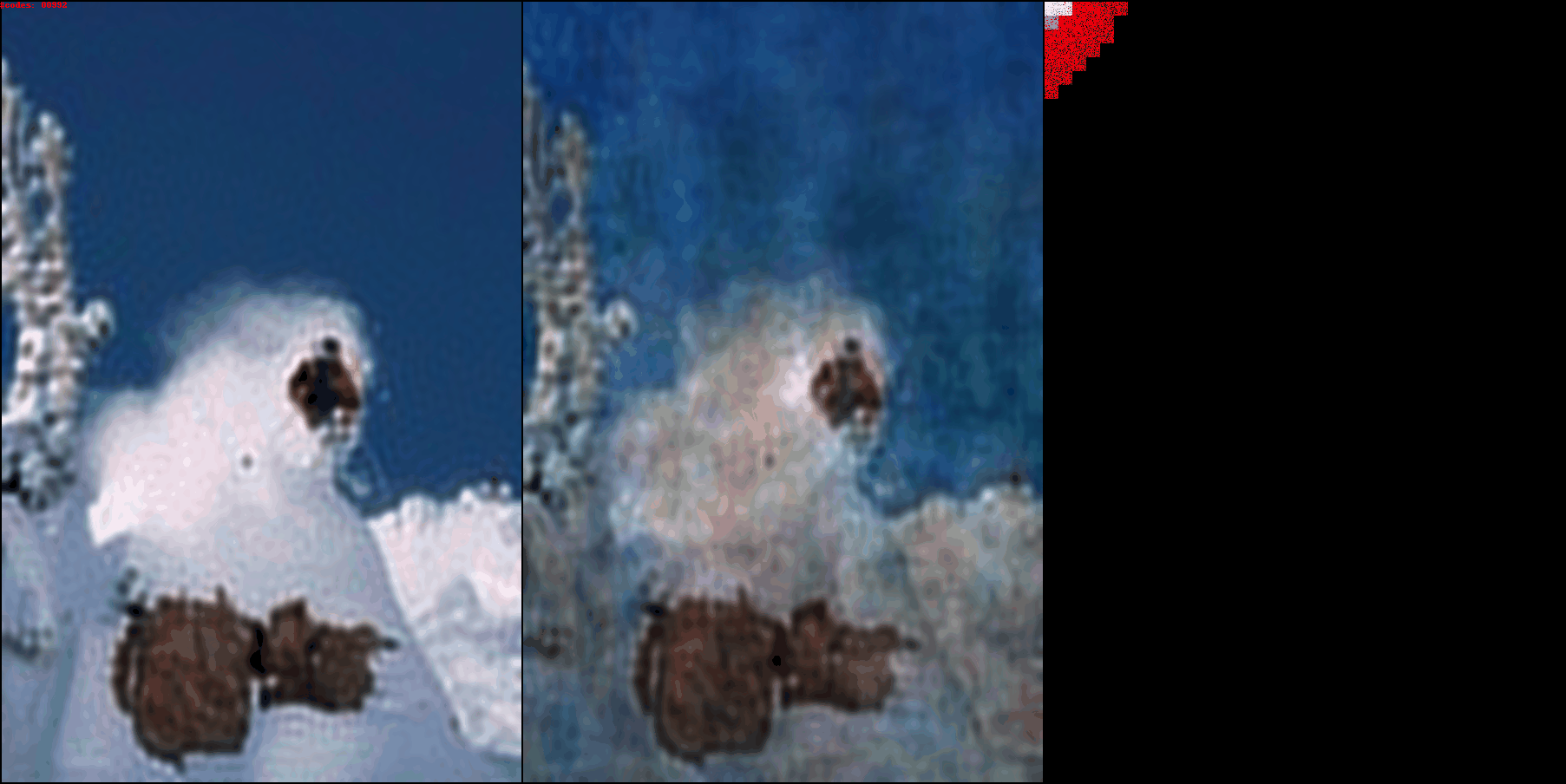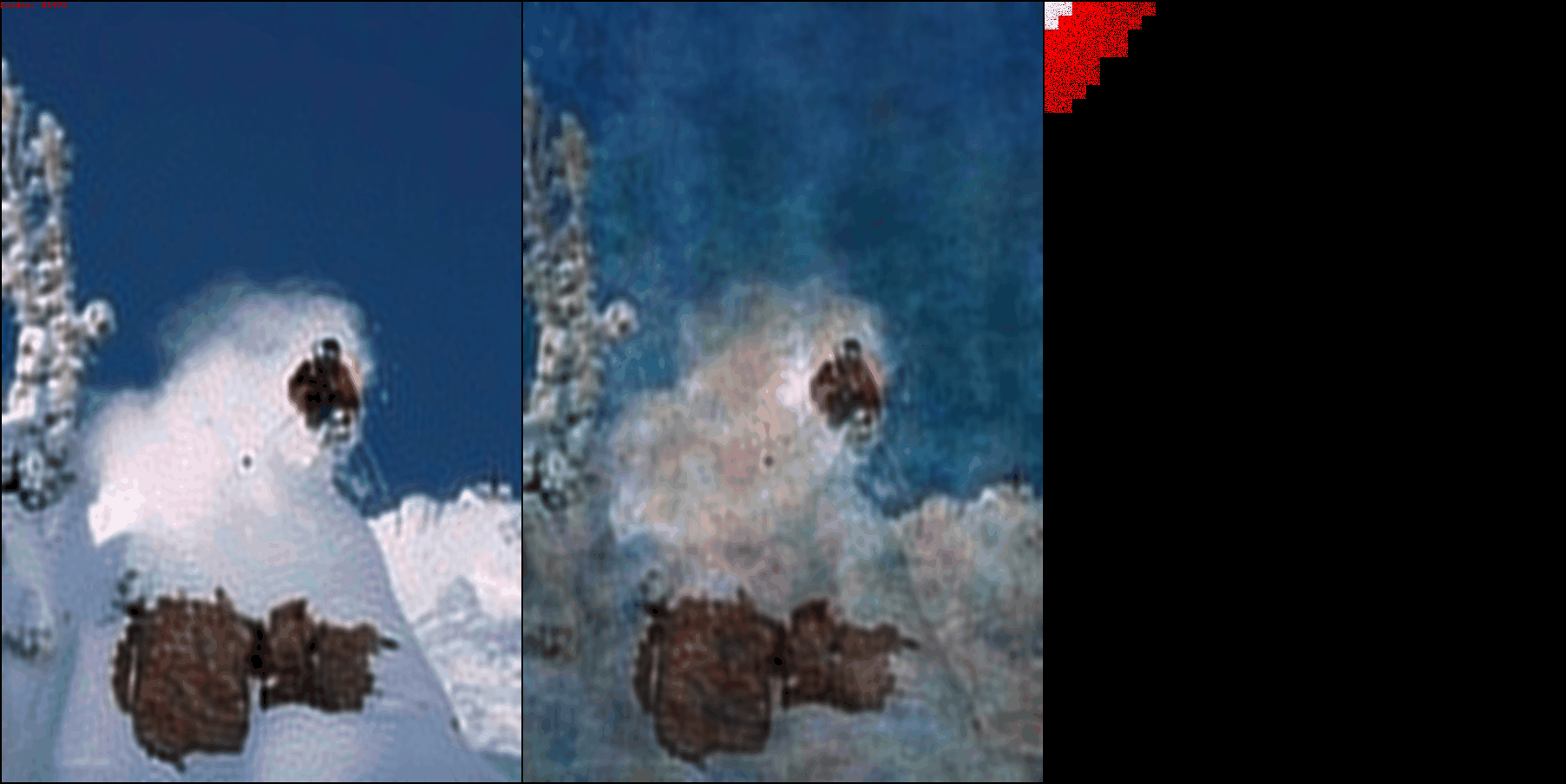
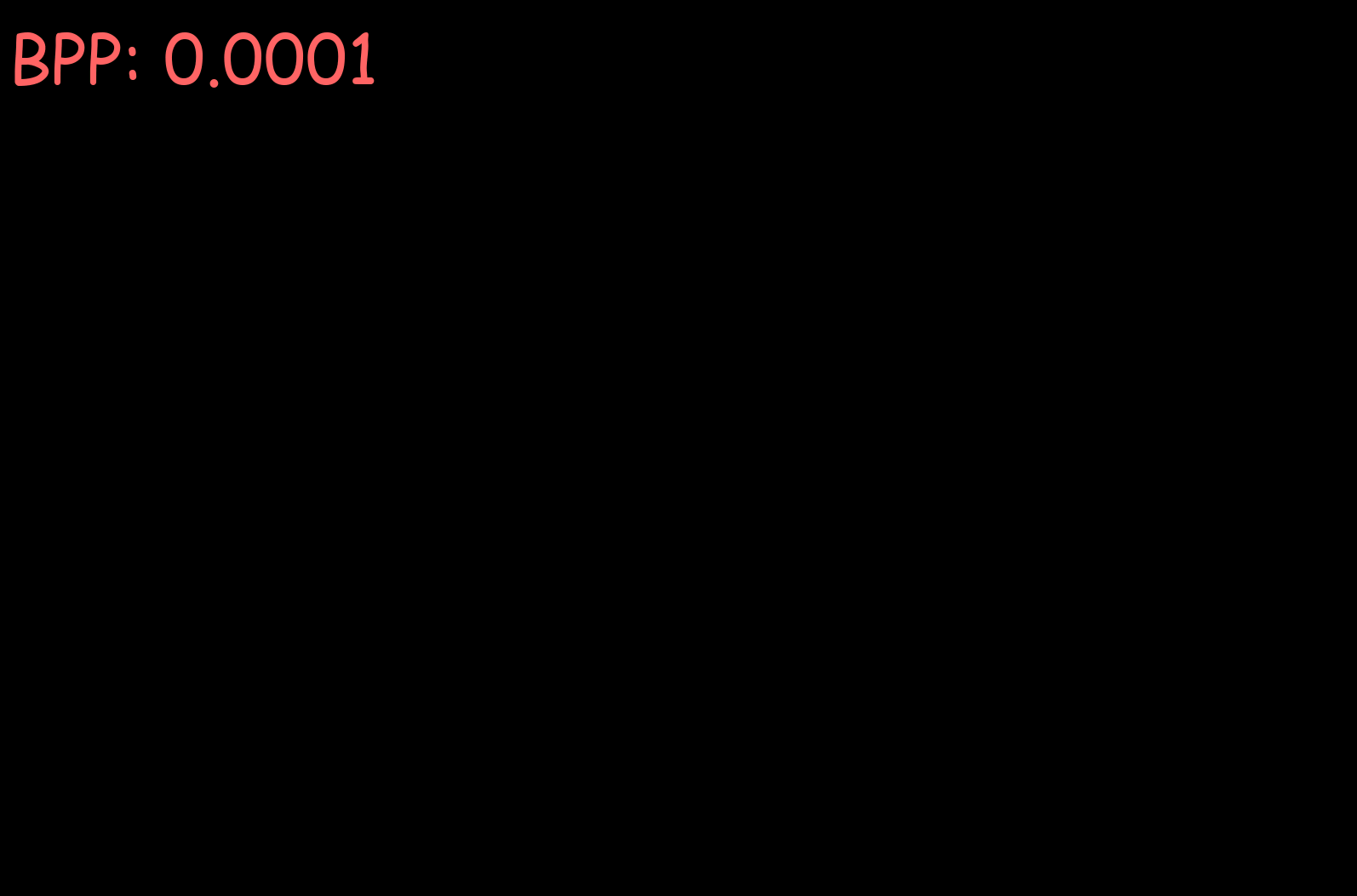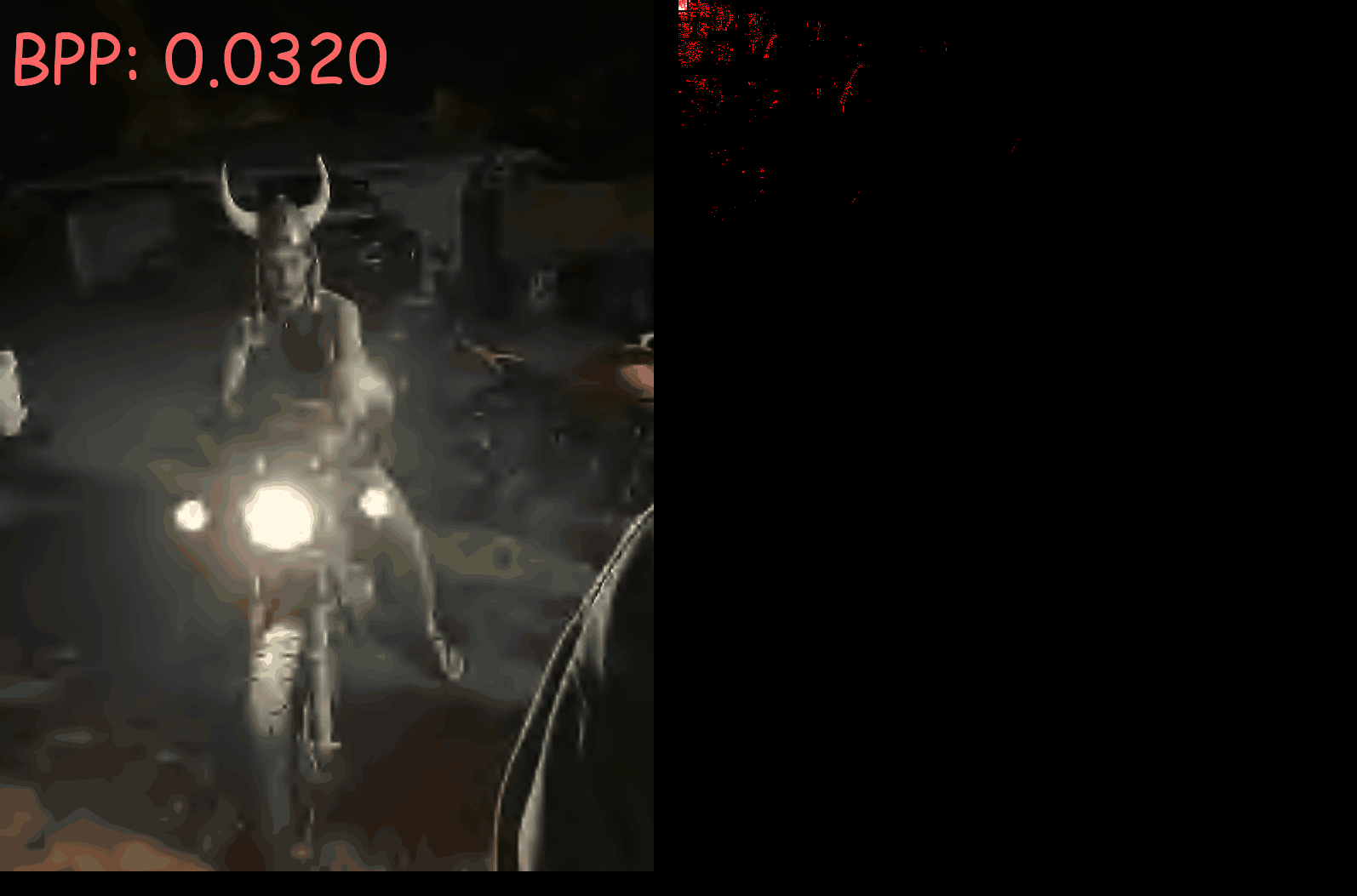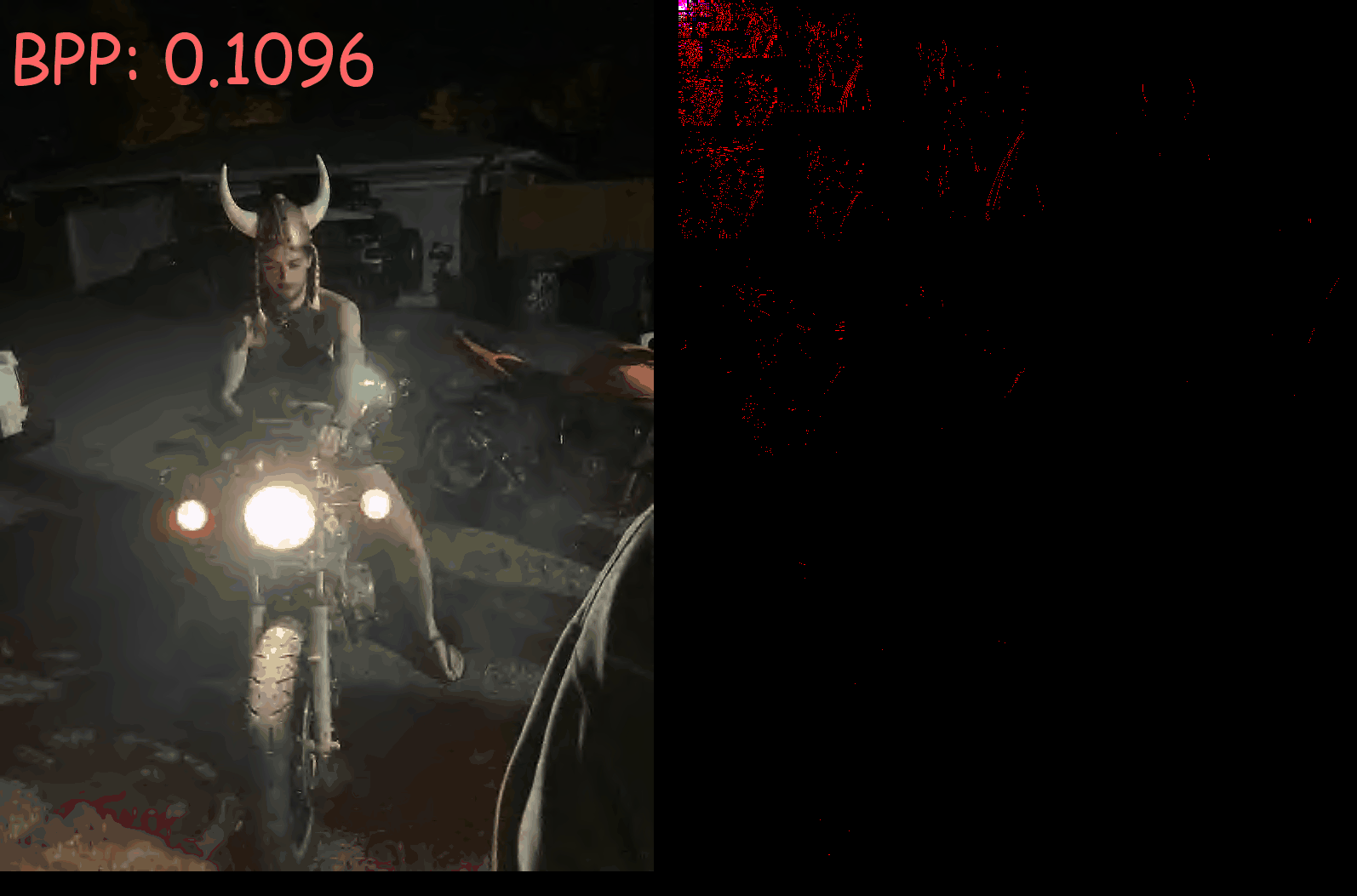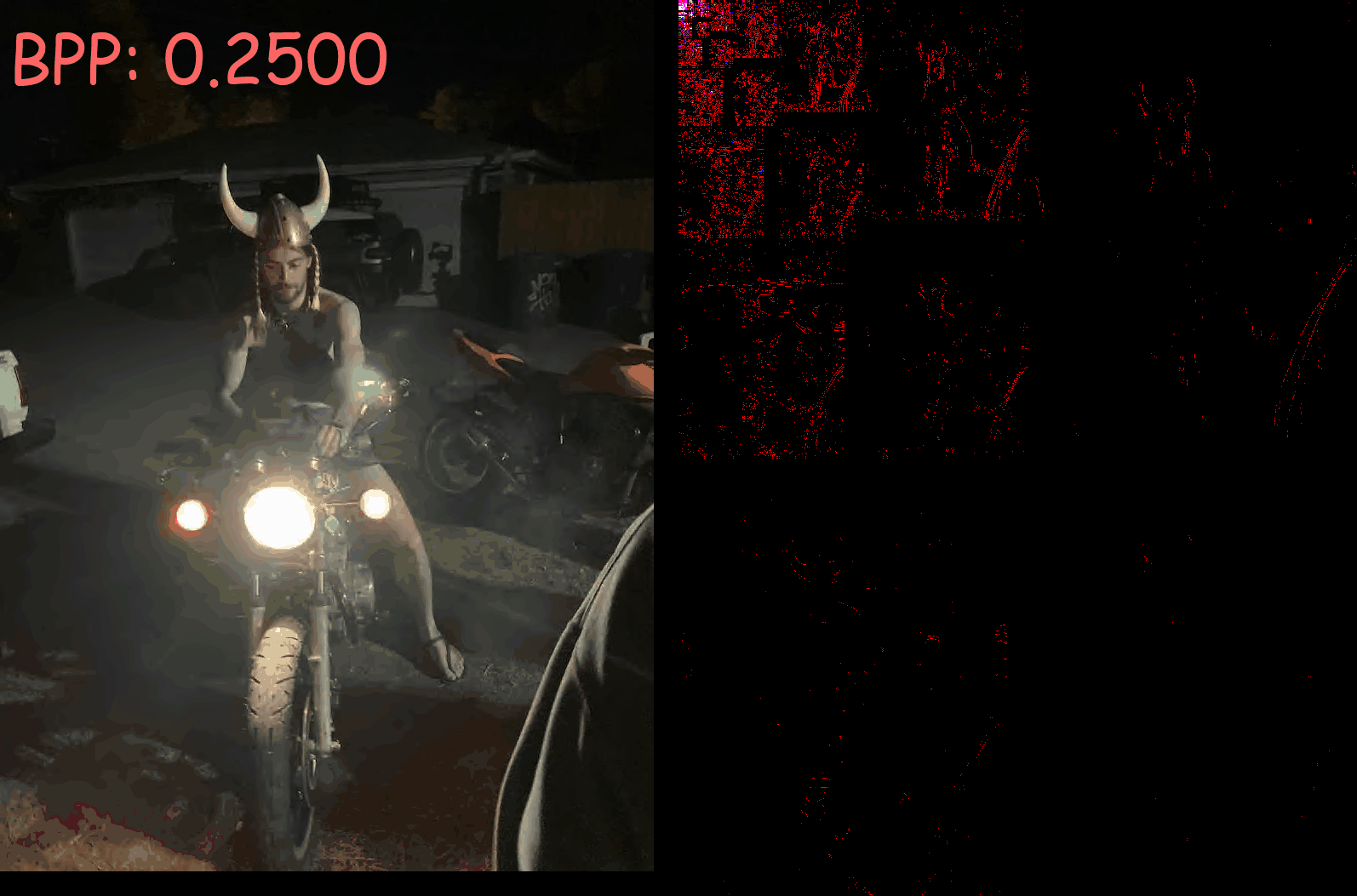 Left: Intermediate decoded image
Left: Intermediate decoded image
Right: Intermediate coefficients from the discrete wavelet transform.
Bits per pixel (BPP) are shown in the top left corner
As BPP increases, you can see how the encoder assigns information to coefficients at higher frequencies. source code available
Left: Intermediate decoded image
Right: Intermediate coefficients from the discrete wavelet transform.
Bits per pixel (BPP) are shown in the top left corner
As BPP increases, you can see how the encoder assigns information to coefficients at higher frequencies.
Your VAE Sucks
A short foray into the Forier transform, JPG, Image Autoencoders, and a new image-autoencoder
architecture inspired by jpg, that produces latent codes with a left-to-right positional
bias.
LLMs and faithfulness to reasoning (blog post): Humans have written a trove of step-by-step explanations and proofs. These
exist on the internet, and some of them end up in the pre-training data for
large language models. Thus, some modicum of step-by-stepedness exists in the
weights of LLMs....
VQ-CLIP: So, you've
heard about
CLIP, but have you heard about
CLIP but with a
Rather than using a real number vector as the embedding, VQ-CLIP uses a list of k integer class IDs. The embedding codes from these models can be used for exiting downstream tasks, such as autregressive CLIP embedding generation.
You can find code+models here
quantized embedding space
??
Rather than using a real number vector as the embedding, VQ-CLIP uses a list of k integer class IDs. The embedding codes from these models can be used for exiting downstream tasks, such as autregressive CLIP embedding generation.
You can find code+models here
Image Retrieval: A Picture is worth 8x8x8 Words: SOTA image retrieval models usually use global real-number embeddings,
obtained from big neural networks. But why is there no love for more
traditional information retrieval techniques such as BoW? Given a 256x256
image, we encode it into a 8x8x8 matrix of discrete integer tokens. We do this
using a ResNet model trained with a learned
vector quantization
layer. Using these tokens, we use

2D Kgrams
to obtain global vectors containing term frequencies.
2D kgrams can be used to produce global representations which capture
spatial relationships
Gravity Market:
A D3 javascript web app which uses a physics simulation to display the percent change in value of various stocks from the S&P 500. This project was made for Vis for Data Science 2022 taught by Dr. Alexander Lex at the University of Utah. Source code to be added soon!
A D3 javascript web app which uses a physics simulation to display the percent change in value of various stocks from the S&P 500. This project was made for Vis for Data Science 2022 taught by Dr. Alexander Lex at the University of Utah. Source code to be added soon!
Songs from Ukraine :
I scraped several hundred gigabytes of social media posts and analyzed the music found in them. Videos were scraped from the Telegram social media platform. Music metadata was retrieved from the videos using Shazam.
Videos were retrieved over the course of months. The scraping process was scheduled using SystemD units on a linux server. CSV metrics on the data were updated asyncronously via file changes. The code for the scraper and data processing was written in Python.
I scraped several hundred gigabytes of social media posts and analyzed the music found in them. Videos were scraped from the Telegram social media platform. Music metadata was retrieved from the videos using Shazam.
Videos were retrieved over the course of months. The scraping process was scheduled using SystemD units on a linux server. CSV metrics on the data were updated asyncronously via file changes. The code for the scraper and data processing was written in Python.
Visualization of a Computationally Derived Fentanyl Binding Protein
:
I used PyMol to create an animation of a binder enzyme as it transitions to the bound state. The program 'Climber' is used to interpolate between the bound and apo states.
I used PyMol to create an animation of a binder enzyme as it transitions to the bound state. The program 'Climber' is used to interpolate between the bound and apo states.
Ascii Art Latent Masked Transformer Model:
I trained a variational quantized autoencoder on ASCII art. The characters in the art are represented as one hot encoded vectors at each 'pixel' in the string. The discrete latents learned by this model were used to train a bidirectional transformer. The transformer was trained to predict masked latent tokens, akin to MaskGit by Google research.
I trained a variational quantized autoencoder on ASCII art. The characters in the art are represented as one hot encoded vectors at each 'pixel' in the string. The discrete latents learned by this model were used to train a bidirectional transformer. The transformer was trained to predict masked latent tokens, akin to MaskGit by Google research.
interpolation of the latent space, the top left corner shows the discrete
tokens, The left ascii art is the decoded representation of the current
embedding. On the right is the original
Ethminer GUI:
A simple cross platform GUI app written in Rust for the ethminer CLI program. It includes capturing of console output from the program, and asyncronous channel communication using Tokio.
A simple cross platform GUI app written in Rust for the ethminer CLI program. It includes capturing of console output from the program, and asyncronous channel communication using Tokio.
Adventures:
How to go from Užice to Bajina Bašta, a Backpacker's guide
Explore the Serbian countryside the simple way by walking
How to go from Romania to Serbia, a Backpacker's guide
Discusses a bio-ecological super low emmision community-driven form of transport
colloquially known as hitchhiking