
Generative modelling of compressed image file bits
Februrary 20th 2024
Tales have long told of a great and mythical image-text architecture. Stories passed down through the generations called it the holy grail. Parents, after a long hard day of prompting, would come home to their children and speak of a day when their tedious prompting would be no more. It would be the holy grail and would generate images using the direct bits/bytes of a compressed file format.
Most called it a fools errand but many were desperate to search for the
grail. Despite much research
others discovered that llms could input and output CLIP
embeddings (Grounding Language Models to Images for Multimodal Inputs and Outputs)
Images and pixels
Images have two dimensions. They have a height and a width. At each position in a 2D grid is a pixel which has 3 bytes that are the pixel's colors. The pixels themselves are captured by a piece of photosensitive material which samples light rebounding off of objects in the real world. The real world is where physics happens and makes light bounce around from stuff going on.
So there are two worlds: pixel world and the real world. Pixel world, though
being just a sample of the real world, can nonetheless still communicate
complicated information about the real world. Sampling down to 2D doesn't rid
all of the intracacies of the real world. Images still have to portray scenes
that portray objects moving through time and 3D space.
Moreover, images aren't restricted to physical 3D objects, they also can show
written text and numbers. Imagine an entity that lives in 2D pixel world and
can only ever see and interact in a 2D plane of existance. Would this entity
have enough information to figure out all of the underlying facts of the real
world that their 2D existence is sampled from?
Images being virtually unrestricted in their expressive power is bad news for our generative models. If we train a model on pixels and we don't specify any other restrictions, we are in effect expecting the model to not only figure out snapshots of the natural world, but also understand all bodies of written text and mathematical proofs and also physics and geometry and psychology and biology. That is why I think people are so eager for an all-in-one holy grail model that does everything. Because the skillsets demanded of LLMs and image gen is the same.
It used to be the case that LMs couldn't generate text with proper grammar and a whole bunch of research was done on decoding within the bounds of correct grammatical sytax. Well, nowdays our image models can't generate within the bounds of physics. I think physics is more complicated than grammar. Why not force our image models to generate within some sort of constrained system?
We aren't designing handmade generation constraints and features these days,
or at not as much as we used to. Models get trained on data that is as close
to the pure input and output modalities as possible, end-to-end. For images
this means means no more SIFT features or handmade edge kernels.
There are still some modelling strategies being used that are less expressive but impose more structure on the inputs and outputs. The model is not given the 'raw' data, it is given a limited version. You're still expecting your model to perform well on the raw data but you only are giving it some gimped version of the data, which is not ideal. If given a choice, most researchers would prefer to use the end to end, but are forced to make concessions for stability or performance reasons. Some examples of this for 3D data are techniques that don't use nerfs Octree transformer where 3D data is generated by autoregressively decoding Octrees, and Mesh GPT for autoregressive generation of vector quantized codings of vertices. For images and sound, the recent paper Bytes Are All You Need: Transformers Operating Directly On File Bytes showed high quality image and sound classification done using the raw bytes of encoded files. These strategies tie in with the idea of constrained decoding. It's similar to generating structured data (like json) with an LLM. Octree-transformer and Mesh GPT during generation have deterministic code than runs in step with the model, allowing and disallowing actions.

To summarize, there's the idea that we divvy our creations up into two distict worlds. The real world, where all the complicated signals are, and the world that programs live in. There is a massive chasm between realness and virtualness. The trend seems to be that machine learning needs to learn from the real world. But I'd argue that the digital world holds a lot, probably enough. I think that it shouldn't matter to train image models on full .RAW images and decode uncompressed pixels and videos. The algorithms that provided the media that fueled the digital boom: html,jpg,mp3, are all handmade and intricate and beautiful. Why should we suddenly desert them? By the 90s we had given up on all of the raw data formats. These encoding algorithms are suboptimal, but they do a fantastic job at linking the real world and the digital world with minimal overhead, and they do it more than well enough for human perception. It shouldn't matter that our models aren't given the real deal.
An image as a left-to-right sequence of tokens
Autoregressive decoder-only token-based transformers work pretty well. They
have an objective that matches well with the idea of max entropy, and they
scale easily, and can usually generate samples matching their data
distribution without many tweaks. For images, the landscape of autoregressive
generation is a bit desolate. Granted, there have been advancements in
discrete modelling of images as a 2D array of tokens. This is not the same as
autoregressive generation though, tokens are sampled from a 2D grid of
probabilities.
Previous works have flattened images in a variety of creative ways. The simplest way to flatten an image into a 1D sequence is to use raster ordering of all pixels. This is what is experimented with in the classic pixel rnn. MEGABYTE used a slightly fancier patch scan order.
Conceptually, raster pixel ordering and even patch scan ordering is a very bad way to treat an image as a sequence of tokens. Image asking a painter to create an art piece by starting in the top left corner, and from there only allowing them to make one brush stroke at every position while moving left-right, top-down in the painting. It would make everything much more difficult for the painter. A more natural way to add detail to a painting over time is to first start with a rough background, then create the overall composition of colors, then add particular strong edges and shapes, and then move in and add fine details to certain areas.
 Bob Ross and other artists do not make paintings by placing brush strokes in a
raster scan ordering.
Bob Ross and other artists do not make paintings by placing brush strokes in a
raster scan ordering.We want to turn an image into a sequence of actions that create the image, in
a way that is easy to explain and follow. In a way, the image itself is a
place for planning. The first actions are noncommittal but set the general
stage for what the image will finally look like. Human artists have a sense of
what to start with when making a painting. Unless you have a dataset of
millions of brush stroke histories we can't really mimic this sequential
behavior.
 Tokenizing an image can be interpreted as translating an image into a sequence
of expert instructions. The instructions have to be 'intuitive', and when followed,
actually result in the creation of something close to the original image. When
we train our LLM to produce the image, we want it to generally mimic these expert
instructions.
Tokenizing an image can be interpreted as translating an image into a sequence
of expert instructions. The instructions have to be 'intuitive', and when followed,
actually result in the creation of something close to the original image. When
we train our LLM to produce the image, we want it to generally mimic these expert
instructions.Image compression algorithm
There are lots of image compression algorithms, but we want one with certain properties. Firstly, the bit-stream should have a left-to-right bias. Secondly, it would be nice if bit stream could be able to be interrupted at any point and decoded into an image. This would let us have previews during the slow autoregressive generation. Also, we want the coding to be very resiliant to noisy tokens. Perhaps most importantly, there should be a way for the decoder/encoder of the compression algorithm to provide extra conditioning information to the autoregressive model about what is going on. We want this property so it removes the burden of the autoregressive model needing to reverse engineer in its weights the compression algorithm.
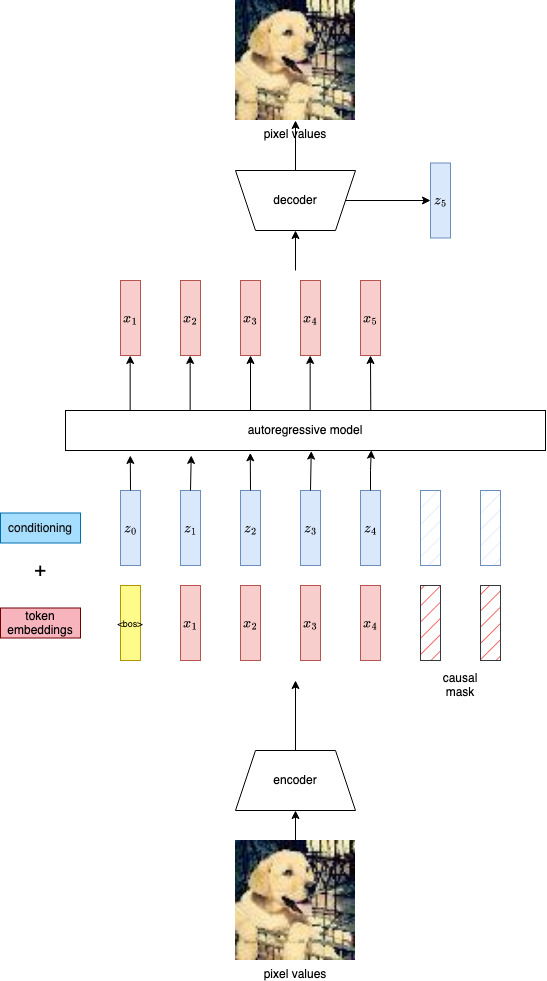 We want to obtain a stream of tokens that describes a sequence of actions to construct
the image. We also want to get conditioning tokens. Conditioning tokens aren't
used directly by the encoder/decoder, but are given as additional information for
the downstream autoregressive generative models. After the autoregressive model
generates each token, it feeds the new sequence to the decoder and gets an additional
conditioning vector. It is difficult to train both the image compression model
and the autoregressive model at the same time and pass gradients between them.
How do we know what information will be useful for the generative model? In this
project I use handmade features.
We want to obtain a stream of tokens that describes a sequence of actions to construct
the image. We also want to get conditioning tokens. Conditioning tokens aren't
used directly by the encoder/decoder, but are given as additional information for
the downstream autoregressive generative models. After the autoregressive model
generates each token, it feeds the new sequence to the decoder and gets an additional
conditioning vector. It is difficult to train both the image compression model
and the autoregressive model at the same time and pass gradients between them.
How do we know what information will be useful for the generative model? In this
project I use handmade features.SPIHT (pdf here) is an old image compression algorithm from the 90s that satisfies many of our requirements. First, it uses the DWT transform to decorrelate RGB pixel values. The DWT decomposition of an image makes a 2D grid of sparse coefficients. They are placed in a way that the coefficients that aren't close to zero are arranged in predictable clusters. Importantly, MSE distance is preserved in the DWT.
The goal of the SPIHT encoder is to output a sequence of bits from most importance to least importance (where importance is measured by MSE between the output image and the current encoded representation). DWT coefficients can be arranged in a tree structure. SPIHT does a kind of BFS of this tree in an ordering of most-to-least significance in the bit plane.
I think SPIHT is better for autoregressive modelling than JPG or JPGXL or HEIC
or png. At any point, the bitstream can be interrupted and the full image
decoded. Each bit has a direct relationship to a single coefficient (or it's
decendents). Each bit is explainable, and clearly attributable to pixels in
the image. It does not use entropy encoding; one bit is one action
BPP stands for bits per pixel. The last image is of size 120 kb
On the right are the DWT coefficients in a packed array
Assisted SPIHT decoding - Conditioning tokens
It's possible to take an AR model, and train it directly on SPIHT bits where each bit is a token. This would be wasteful because it completely discards all advantage of how explainable each bit of the SPIHT encoding is. By default, by just training on the bits themselves, we're basically expecting the NN model to fully memorize how the decoding algorithm works and the current variables at each step of the SPIHT decoder/encoder. SPIHT is close to being a tree decoding algorithm. You can 'tell' the NN where it is in the tree at each next token. We can infuse our input tokens with extra information about the current state of the SPIHT decoder right as it is consuming the next bit. This is information that is available during inference time.
What can be used from the spiht algorithm as conditioning at each bit? There's
the height and width and channel position of the next coefficient to be
queried.
Spihtter
Put altogether I call this model architecture 'Spihtter'. Spihtter inputs and outputs a left to right sequence of discrete tokens. It recieves additional embeddings per-token, representing the state of the spiht decoder. Technically, any model could be used to produce next token logits.
The only tricky part is keeping the model fed with spiht metadata during inference. Per generated token, this is a linear time operation. But you have to keep track of where you are in the SPIHT decoding algorithm. I implemented a spiht encoder/decoder in rust which is used to build a dataset of training examples. During inference I use a different python implementation of the spiht algorithm. I do this so I can use python's yield feature and access spiht bits in a stream.
I place image bits inside of html tags, like this: <spiht h=28 w=28
n=11101>010101011110111101</spiht>
Spiht needs some extra information to start decoding. Namely, the height and width
and starting value of the variable 'n'. I encode these values as html attributes.
Experiments
All experiments can be reproduced from the code base here: https://github.com/theAdamColton/spihtterI train different Spihtter models on some small toy datasets. I am currently gpu poor and did these small experiments using an M1 macbook air with 8GB of memory.
For generation I use greedy search. I did not play around with sampling settings. I left hyperparameters at their recommended values
MNIST
28x28 greyscale MNIST digits can be encoded in as few as 256 tokens using SPIHT. The small llama model can be trained to produce coherent digits in a very short wall clock time, about 4 minutes. Mamba fails to produce correct mnist digits.


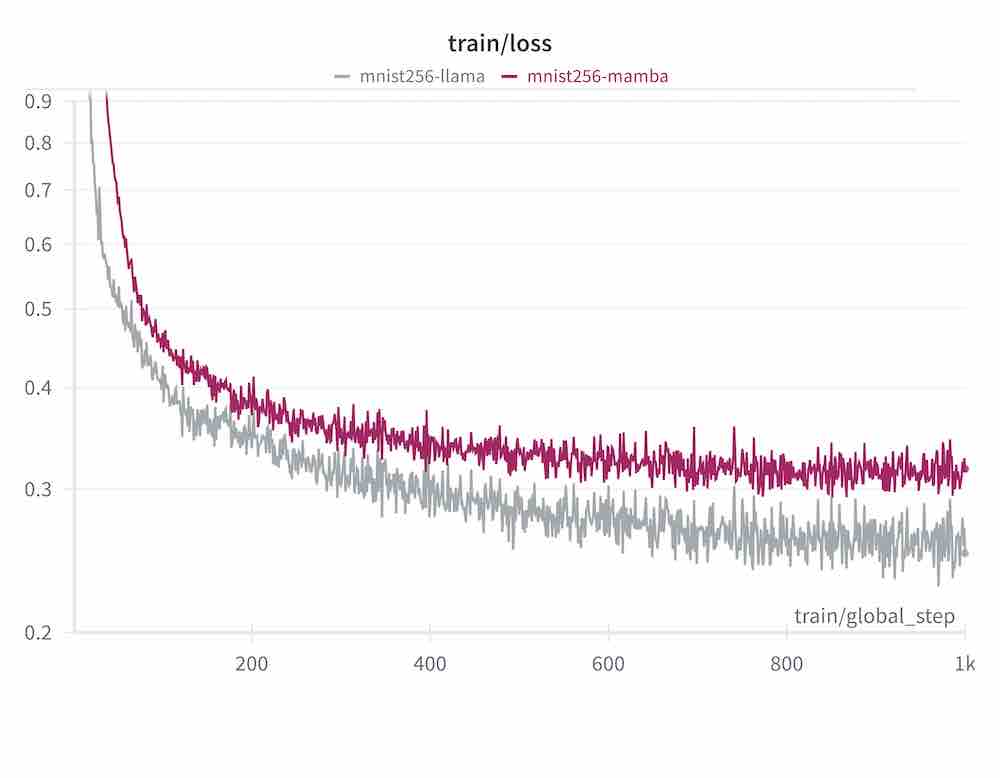 mamba: purple, vs llama: grey, NLL loss. To be fair, LLaMa had almost 10x the number
of parameters, but also trained 6x faster.
mamba: purple, vs llama: grey, NLL loss. To be fair, LLaMa had almost 10x the number
of parameters, but also trained 6x faster.
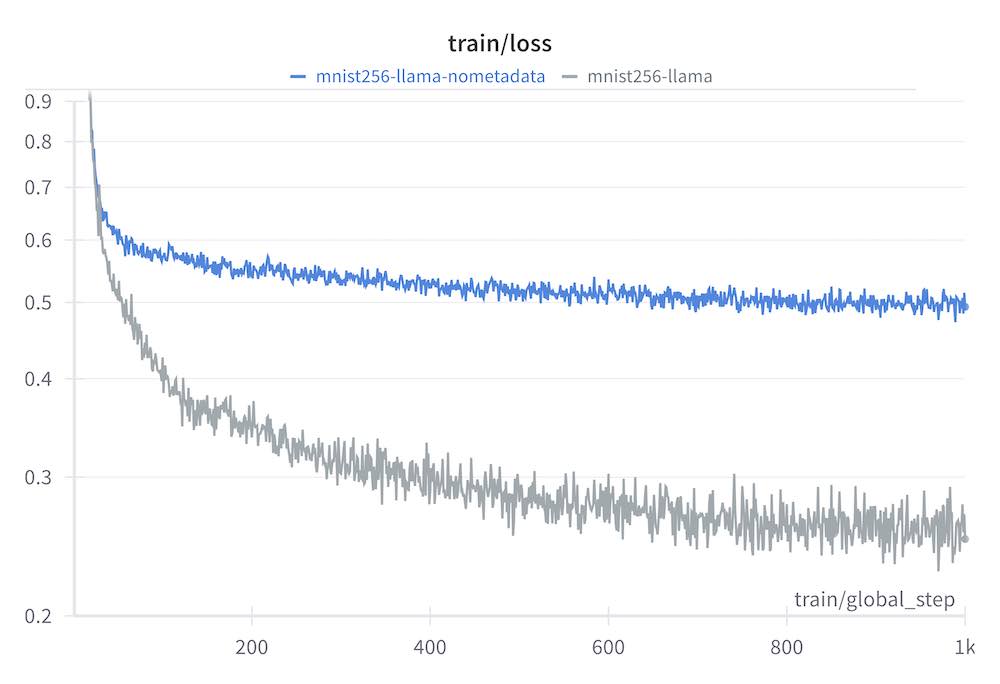 The blue loss curve is without any conditioning information from the spiht decoder.
The grey loss curve is from giving the LLM embeddings based on the internal programmatic
state of the spiht decoder. The conditioning information from the spiht algorithm
vastly improves the ability to model the sequence. model used: llama-small.json
The blue loss curve is without any conditioning information from the spiht decoder.
The grey loss curve is from giving the LLM embeddings based on the internal programmatic
state of the spiht decoder. The conditioning information from the spiht algorithm
vastly improves the ability to model the sequence. model used: llama-small.jsonThe mamba model didn't match the performance of the llama model. I don't want to be overly critical. I'm relying on a hacked together implementation. I couldn't train using the 'MPS' device because 4D cumsum is not supported as of pytorch 2.2.3. So the training time was much longer. Worryingly, throughout training, most of the images generated from the 0-9 digits are exactly the same. I checked for bugs and couldn't find any; the mamba model is receiving the proper labels, but it seems that the information from the class label at the start of the sequence goes completely forgotten.
Future work
I figured out that you can use spiht to encode latents from the stable diffusion VAE. It make perfect sense why it works. It looks kinda trippy, and the reconstruction quality is quite high at around .25 bpp for most images. I'm doing more research on neural image compression so I'm going to come back to this topic later once I understand the literature better.
There are some artifacts, but you get a good image at around 0.25 bpp
Using this trick you can get good images at around ~25k bits. It's also extremely useful if you are trying to save a huge dataset of VAE embeddings on disk. You can just save them as torch tensors, but using spiht as lossy compression you can save 60% of the disk space.
Again, it seems like the quest for the holy grail will have to continue.