
Small LLMs Have a Big Problem
I discuss and verify a widely know issue with the LLM architecture. The token embedding and LM head are memory and gradient bottlenecks. Replacing these two pieces with a bits-centric denoising head solves the issues when tested on a toy problem. I demonstrate that the bits-centric approach cannot however scale to testing on textual pretraining.
March 20th 2026LLMs Fail at this Simple Toy Problem
I create a simple toy dataset where the first token is sampled randomly from
the vocab size of the LLM, and the remaining tokens are taken as the same as
the first. For example, the first token is random.randint(0, 1-vocab_size) and the remaining tokens in the sequence are the same as the first.
I train a small 70 million parameter auto regressive LLM on these sequences for 50,000 steps. Lo and behold it cannot learn it at ALL.
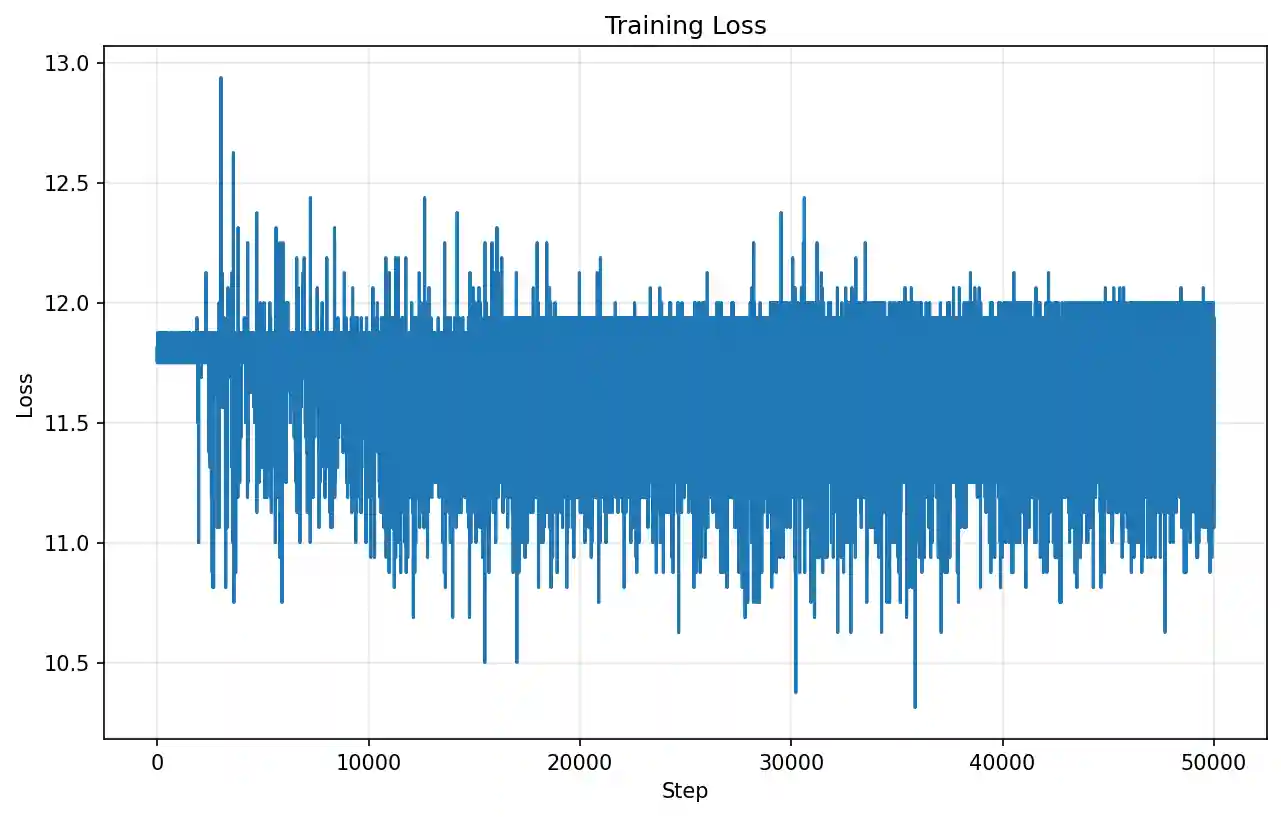 Cross entropy training loss of vanilla LLM trained on SpamLang.
Cross entropy training loss of vanilla LLM trained on SpamLang.For example, with a prefix of 117385, 117385, 117385, 117385, 117385, 117385, 117385, 117385, the fully trained vanilla model autoregresively generates this
continuation:
55571, 55571, 55571, 55571, 55571, 55571, 55571, 55571, ...
All it has to do is learn how to copy the tokens in the prompt and repeat them
a bunch of times! Why can't it learn this simple pattern?
Why it fails and one potential solution
My first thought is that its failure is obvious. Consider that I only train the model for 50,000 steps at a batch size of 1. That means with its vocab_size of 131072 it only sees about 38% of the possible SpamLang samples. The remaining 62% of the token_embeddings receive absolutely zero gradients whatsoever. But despite this seeming like a trivial issue resolved through more data I feel like it is a fundamental flaw in the way LLMs treat language tokens.
More data and more compute can solve anything. But what if we want small
models trained with small compute? LLM researchers seem not to care much about
training impoverished models but we can find answers from the field of image
generation where researchers train much smaller models with much fewer
training samples. Usually images are generated using continuous latents or
pixels but there is a less common paradigm of generating discrete image
tokens in a similar way that LLMs generate discrete language tokens.
Researchers have noticed that these small image models fail to fit to images
tokenized with very large vocab sizes. Recently a paper from BitDance
demonstrated a promising potential solution to this problem.
[arxiv]
Simply replacing the bit diffusion head is not enough to solve the toy
problem. The token embedding still has the issue that 62% of the token
embeddings are never used. So I made a modified bit-centric LLM with both a
bit-embedding and a bit-diffusion head. Instead of using a learnable vector
embedding for each of the m
possible token ids, I use a linear projection that projects the
log2(m) bits of the token id into the models hidden size. I
replace the d*m LM head with a 2 layer MLP bit diffusion head.
The bit diffusion head doesn't output logits like the vanilla LLM. Instead it
takes as input the noisy bits of a token_id and a feature vector from the
transformer backbone. The head gradually denoises the bits and then
discretizes them and converts the bits back to an integer token id.
I train this bit-centric model on the SpamLang dataset using the same training settings. The differences are stark. Within 20,000 training steps the bit-centric LLM completely learns the pattern.
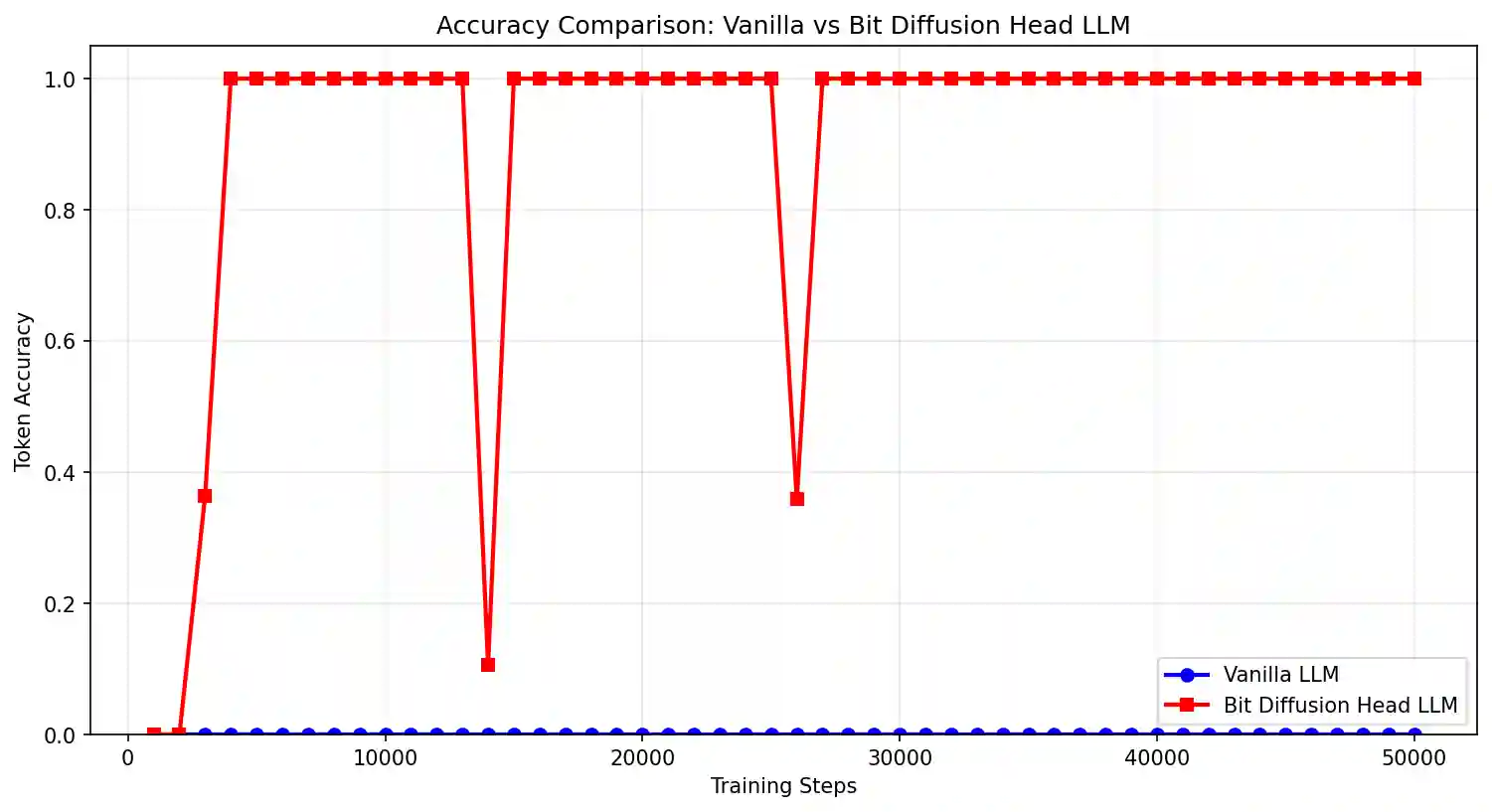 Autoregressive accuracy of Vanilla LLM vs Bit-centric LLM. Models are given the
first 51 repeating tokens and need to autoregressively predict the remaining 205
tokens.
Autoregressive accuracy of Vanilla LLM vs Bit-centric LLM. Models are given the
first 51 repeating tokens and need to autoregressively predict the remaining 205
tokens.To the bit diffusion model this pattern is simple to learn. It doesn't matter that it is only every trained on 38% of the possible token ids because it learns a generalizable pattern that operates on the bits of the token ids instead of directly on the very large space of token ids.
"Awesome!", you might be thinking, "Let's all switch to bit-centric LLMs!".
Not so fast - I want to first see if this can work on real language tokens
from real datasets. It may be the case that the Vanilla LLM fails miserably on
the SpamLang dataset but excels on the real data. After all, bits are not a
intuitive natural representation of language. Before jumping to any
conclusions I want to compare the vanilla LLM to the bit-centric LLM on a real
dataset.
FinePhrase - Do bit-centric LLMs work at scale?
Emboldened by bit-diffusion's good performance on the toy dataset I set out to test it at a larger scale. I trained both a 90 million parameter vanilla LLM and a 25 million parameter bit diffusion LLM on 3 billion tokens from the finephrase dataset.
It's hard to compare apples-to-apples between the bit diffusion LLM and the vanilla LLM because small LLMs with large vocab size have their parameter count and compute budget dominated by the LM head. For example, a vanilla LLM with 90M parameters has a transformer hidden dimension of 256 with 12 layers. A 25M parameter bit-diffusion model can have a hidden dimension of 384 with 12 layers. At such small scales the vanilla LLM devotes a huge proportion of its parameters and compute to the LM head.
The training speeds are also quite different. The vanilla LLM's training step
takes about 2 seconds and consumes 32 GB of device memory. batch_size*vocab_size*sequence_length logits tensor
For simplicity I opt to train a single 90M vanilla LLM from scratch and use it as a baseline to compare against a variety of different bit diffusion models. Because the vanilla LLM objective is widely understood and so easily implemented I only have to train a single model in order to get decent results.
Usually the simplest way to compare performance between different pretrained LLM architectures is to compare perplexity computed over a test set. However, the bit-diffusion-head doesn't output probabilities so I instead compare runs by getting the model to generate a continuation to a simple prompt.
Table 1.
| Method | Tokenizer Type | # backbone params (millions> | # non-backbone params (millions> | Trained Tokens (billions) | Prompt and generated output |
|---|---|---|---|---|---|
| Vanilla CrossEntropy | Qwen3 | 10 | 80 | 4 | A water bird, alternatively waterbird or aquatic bird, is a species of bird that lives in the water. It is also known as the “waterbird” because it feeds on aquatic insects and other aquatic organisms. Waterbirds are found throughout the world, including the Americas, Africa, Australia, New Zealand, North America, and more. ✅ |
| bit diffusion head | Qwen3 converted to bits | 24 | 1 | 2.5 | A water bird, alternatively waterbird or aquatic bird, Credit/logo size The waterords to pills and bookedeline on the(constBuffer unacts and separate com.ofengineers. As th e rare wood} BetterLowTypater_precision standard and its backge } BetterLowTypater_precision standard and its backge 😭 |
| bit diffusion head | Qwen3 converted to hierarchical bits | 90 | 10 | 1.5 | A water bird, alternatively waterbird or aquatic bird, has a healthy habitat for the roof's plants and landscapes.\nA few rating words:\n- P Constructors 1/0/15KHistorian school coupleDenaraycler > 😭 |
Table 1. shows the generation from the bit diffusion model fall far behind the vanilla LLM. It is not even remotely coherent, while the vanilla LLM writes something somewhat reasonable. I was disappointed on seeing these poor results and set out to try and figure out a way to close the gap.
I went back to the drawing board and looked again at the BitDance paper that
my bit-diffusion-head is based on. Why does the bit-diffusion-head work so
well for them? I think the main reason is that the bits that it learns to
diffuse are directly meaningful. The bits come from the LFQ
The bits need to better represent the underlying token's semantic content. For example, the first bit should be something like 'Is this token a verb or a noun' and the second bit could be something like 'Is this token English or Mandarin'.
Hierarchical bit tokenizer
I want to convert tokens to bits in a way that the each bit encodes something important about the token and a token's bits are a unique and invertible mapping. My previous design of converting the token_ids to little-endian bits satisfied the latter but not the former.
Qwen3.5's pretrained token embedding contains some encoded representation of each token. I assume that the euclidean distance between two different token embeddings has some measure of semantic similarity. I can use these embeddings as inputs to a clustering algorithm. At each step of the algorithm I run k-means on the token embeddings with k=2 groups. I use the groups to bisect the tokens, assigning tokens in the first group with a bit of 0 and the second group with a bit of 1. I do this recursively until all of the n tokens are assigned log2(n) bits. This organizes tokens into a binary tree. The bits uniquely identify each token and they better represent a token's semantic content because they encode its clustered group.
After converting the vocab into a the better hierarchical bits I retrain the model using this new tokenizer. To make things more even with the vanilla LLM, I expand the model's hidden size to match the number of parameters as the vanilla model. I train for 1.5 billion tokens but unfortunately the outputs never come close to the coherence of the vanilla LLM.
Conclusion
I'll leave this as a testament that the vanilla LLM baselines is very finely tuned and hard to crack. I've learned a lot about the bottlenecks when training small LLMs. They can converge and output surprisingly good tokens but need special handling for large vocab sizes. Maybe LLMs of the future will always use tokens and logits, or maybe they will switch to something completely different. Perhaps they will always use OCR to process the prompt with a vision transformer, but generate discrete tokens like normal. Or perhaps they will only input and ouput visual fonts like a human does.
At this point embedding a huge vocabulary into images isn't the most radical idea. I look forward to seeing what cool new LLMs we design in the future.